
{kind=link}
AMD unveils AMD OLMo, its first 1B-parameter LLM with strong reasoning
AMD has introduced its first series of fully open-source 1-billion-parameter large language models (LLMs), called AMD OLMo that is aimed at a variety of applications and pre-trained on the company’s Instinct MI250 GPUs. The LLMs are said to offer strong reasoning, instruction-following, and chat capabilities.
AMD’s open source LLMs are meant to improve the company’s position in the AI industry and enable its clients (and everyone else) to deploy these open-source models with AMD’s hardware. By open-sourcing the data, weights, training recipes, and code, AMD aims to empower developers to not only replicate the models but also build upon them for further innovation. Beyond use in datacenters, AMD has enabled local deployment of OLMo models on AMD Ryzen AI PCs equipped with neural processing units (NPUs), enabling developers to leverage AI models on personal devices.
Multi-stage pre-training
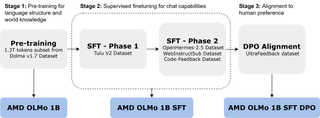
The AMD OLMo models were trained on a vast dataset of 1.3 trillion tokens on 16 nodes, each with four AMD Instinct MI250 GPUs (64 processors in total). AMD’s OLMo model lineup was trained in three steps.

- The initial AMD OLMo 1B pre-trained on a subset of Dolma v1.7 is a decoder-only transformer focused on next-token prediction to capture language patterns and general knowledge.
- The second version is AMD OLMo 1B supervised fine-tuned (SFT) was trained on on Tulu V2 dataset (1st phase) and then OpenHermes-2.5, WebInstructSub, and Code-Feedback datasets (2nd phase) to refine its instruction-following and improved its performance on tasks involving science, coding, and mathematics.
- After fine-tuning, the AMD OLMo 1B SFT model was aligned to human preferences using Direct Preference Optimization (DPO) with the UltraFeedback dataset, leading to the final AMD OLMo 1B SFT DPO version to prioritize outputs that align with typical human feedback.
Performance results
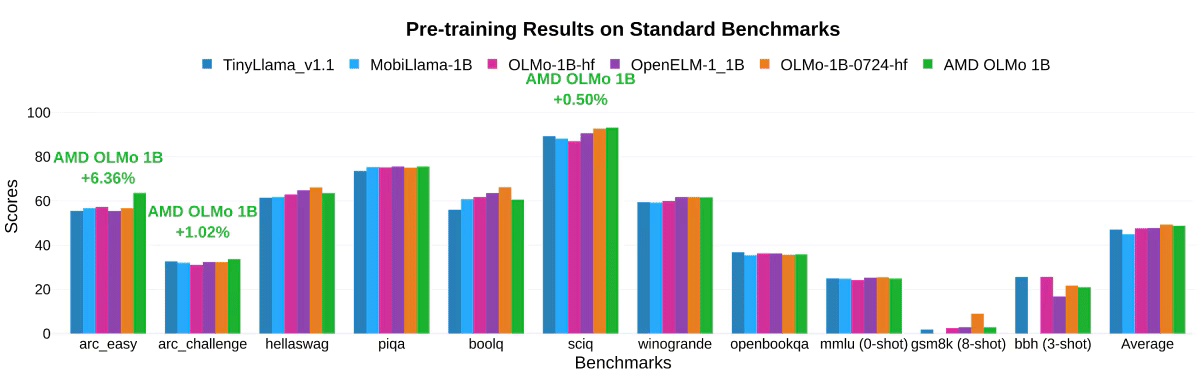
In AMD’s own testing, AMD OLMo models showed impressive performance against similarly sized open-source models, such as TinyLlama-1.1B, MobiLlama-1B, and OpenELM-1_1B in standard benchmarks for general reasoning capabilities and multi-task understanding.

The two-phase SFT model saw significant accuracy improvements, with MMLU scores increasing by 5.09%, and GSM8k by 15.32%, which shows impact of AMD’s training approach. The final AMD OLMo 1B SFT DPO model outperformed other open-source chat models by at least 2.60% on average across benchmarks.

When it comes to instruction-tuning results of AMD OLMo models on chat benchmarks, specifically comparing the AMD OLMo 1B SFT and AMD OLMo 1B SFT DPO models with other instruction-tuned models, AMD’s models outperformed the next best rival in AlpacaEval 2 Win Rate by +3.41% and AlpacaEval 2 LC Win Rate by +2.29%. Additionally, in the MT-Bench test, which measures multi-turn chat capabilities, the SFT DPO model achieved a +0.97% performance gain over its closest competitor.
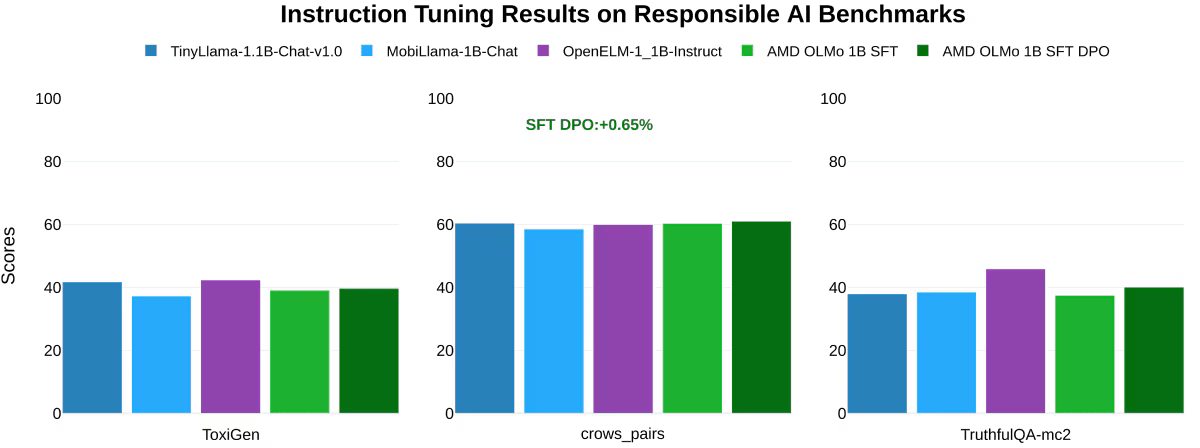
Additionally, AMD tested responsible AI benchmarks, such as ToxiGen (which measures toxic language, where a lower score is better), crows_pairs (evaluating bias), and TruthfulQA-mc2 (assessing truthfulness in responses). It was found that the AMD OLMo models were on par with similar models in handling ethical and responsible AI tasks.
#AMD #unveils #AMD #OLMo #1Bparameter #LLM #strong #reasoning