
Intel Launches Granite Rapids Xeon 6900P series with 120 cores — matches AMD EPYC’s core counts for the first time since 2017
Intel announced the on-time launch of its high-performance Xen 6 ‘Granite Rapids’ 6900P-series models today, with five new models spanning from 72 cores up to 128 cores, finally exceeding the core counts of AMD’s existing EPYC models for the first time since 2017, and even matching the core counts of AMD’s soon-to-be-launched Zen 5 Turin processors. As a result of numerous enhancements, Intel claims the 6900P series provides up to 2.1x the performance of AMD’s competing 96-core Genoa flagship in the OpenFOAM HPC workload, and up to 5.5x the AI inferencing performance in ResNet50.
Intel’s claims are impressive against AMD’s current-gen models, but AMD has its 3nm EPYC Turin retort with up to 128 performance cores coming next month, setting the stage for a pitched battle for data center sockets throughout the remainder of 2024 and into 2025.
Image 1 of 4

{kind=link}
Intel unveiled its new Xeon 6 processors at its Enterprise Tech Tour event in Portland, Oregon, last week, and it also showed its exceedingly important next-gen Clearwater Forest for the first time.
The new flagship Xeon 6 data center processors come with new CPU core microarchitectures, the Intel 3 process node, and up to 504MB of L3 cache, along with support for 12 memory channels and MRDIMM memory tech that enables speeds reaching up to 8800 MT/s, all of which intel says contributes to strong gen-on-gen performance and power efficiency gains. Intel shared plenty of benchmarks to back up those claims, which we’ll also cover below.
Xeon 6 Models and Platforms
Image 1 of 4
Intel has split its Xeon 6 ‘Granite Rapids’ family into several swim lanes. The Granite Rapids 6900P lineup launching today employs all performance cores (P-cores) for latency-sensitive workloads and environments that prize high single-core performance, making them a good fit for HPC, AI, virtualized environments, and general workloads.
The five 6900P models range from 72 to 128 cores and stretch up to an unprecedented 500W TDP (AMD’s Turin is expected to have similar TDPs). Intel’s new models also have up to an incredible 504MB of L3 cache, also beating out AMD’s current-gen Genoa models.
| Model | Price | Cores/Threads | Base/Boost (GHz) | TDP | L3 Cache (MB) | cTDP (W) |
|---|---|---|---|---|---|---|
| Xeon 6980P (GNR) | $? | 128 / 256 | 2.0 / 3.9 | 500W | 504 | – |
| Xeon 6979P (GNR) | $? | 120 / 240 | 2.1 / 3.9 | 500W | 504 | – |
| EPYC Genoa 9654 | $11,805 | 96 / 192 | 2.4 / 3.7 | 360W | 384 | 320-400 |
| Xeon 6972P (GNR) | $? | 96 / 192 | 2.4 / 3.9 | 500W | 480 | – |
| EPYC Genoa 9634 | $10,304 | 84 / 168 | 2.25 / 3.7 | 290W | 384 | 240-300 |
| Xeon 6960P (GNR) | $? | 72 / 144 | 2.7 / 3.9 | 500W | 432 | – |
| Intel Xeon 8592+ (EMR) | $11,600 | 64 / 128 | 1.9 / 3.9 | 350W | 320 | – |
| EPYC Genoa 9554 | $9,087 | 64 / 128 | 3.1 / 3.75 | 360W | 256 | 320-400 |
Intel will launch the more general-purpose P-core Xeon 6 models with 86 or fewer cores in the first quarter of 2025 (more info below). Of course, the list of 6900P SKUs only includes ‘on-roadmap’ models, but Intel also works with partners to deliver custom chip designs based on their needs (AWS is a recent example). In the past, Intel has said that custom models comprise up to 50% of its Xeon sales, but the current distribution is unclear.
Intel launched its Xeon 6 ‘Sierra Forest’ 6700E series models earlier this year. These processors come armed with up to 144 efficiency cores (E-cores) for density-optimized environments that prize performance-per-watt. Intel’s 6900E models with up to 288 single-threaded efficiency cores will also arrive in Q1 2025, exceeding AMD’s core counts for the density-optimized Zen 5c Turin models that will come with 192 cores. However, Turin supports simultaneous multithreading (SMT), so those chips have up to 384 threads — we’ll have to see how the differences pan out in actual benchmarks.
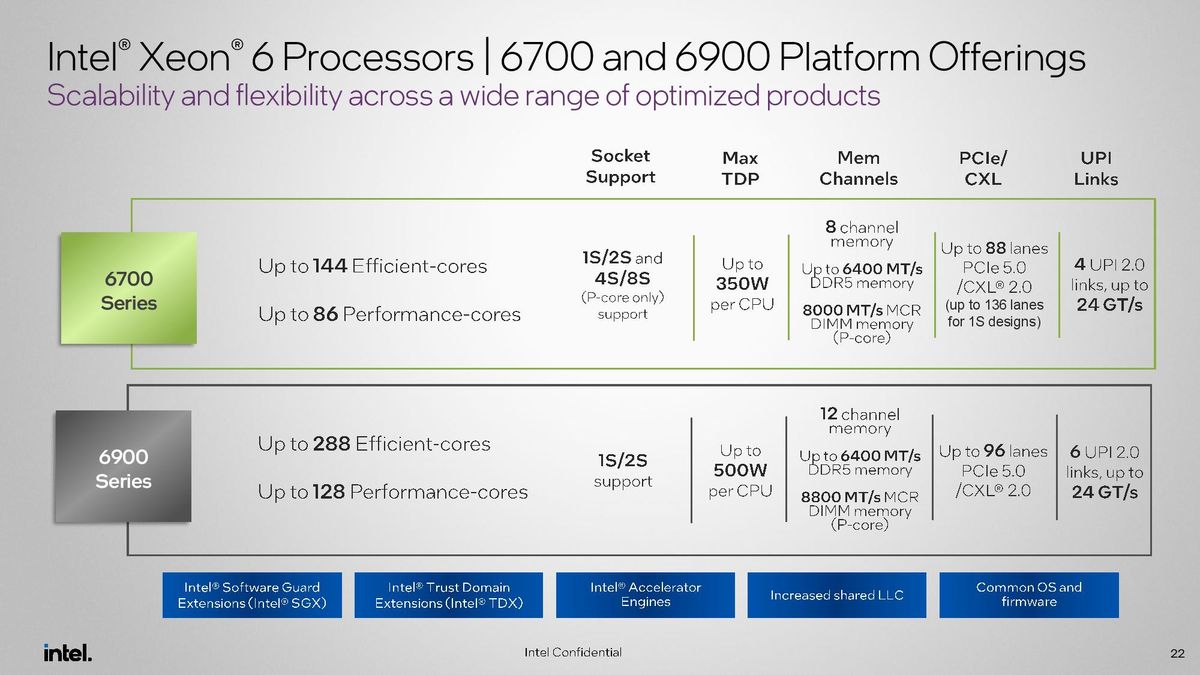
Both types of Granite Rapids processors drop into the Birch Stream platform, but Intel also splits this into two distinct branches. The Xeon 6700 E/P series will slot into standard SP server platforms, which support up to either 86 P-cores or 144 E-cores, up to 350W per CPU, eight memory channels, and up to eight sockets per server.
The 6900 E/P series models require AP (Advanced Performance) server platforms that support up to 128 P-cores or 288 E-cores, up to 500W per CPU, 12 memory channels, and two sockets per server. Intel’s original somewhat exotic AP platforms, which debuted with the Cascade Lake generation, didn’t get much uptake due to a limited number of available system designs. Intel’s executives tell us the demand for AP systems is far more robust given the current need for more performance density, and many more OEMs will bring AP platforms to market.
The future Clearwater Forest chips with the 18A process will also be supported on the Birch Stream platform, providing forward compatibility for customers and OEMs.
Xeon 6900P Granite Rapids Architecture
Image 1 of 4
We’ve covered the Granite Rapids architecture multiple times in the past, but here’s a short overview.
Intel’s 6700P series consists of designs with three compute dies (UCC designator), which are fabbed on the Intel 3 process node and house the CPU cores with the Redwood Cove microarchitecture, caches, interconnect mesh, and memory controllers. Intel isn’t disclosing the number of physical CPU cores present on each die, but it’s a safe assumption that each die has a minimum of one extra physical CPU core to help defray the impact of defects, thus improving yield.
Four memory controllers are attached to each of the compute die, which can create latency penalties for cross-die accesses. Intel offers both a standard HEX mode that allows accessing all dies as one pool and an SNC3 mode that restricts memory and L3 cache access to each local compute die, thus avoiding the latency impact. This is similar to the traditional Sub-Numa Clustering (SNC) modes on prior-gen models; we’ll put these modes to the test in our pending review.
Two I/O dies are included in each chip, regardless of specs, to keep the I/O capabilities consistent across models. The I/O dies are fabbed on the Intel 7 process node and house the PCIe, UPI, and CXL controllers along with the I/O fabric.
Intel is releasing the triple-compute-die UCC models today, but the XCC, HCC, and LCC models with fewer cores/die will arrive in Q1 2025.
The I/O die also houses the in-built QAT, DLB, DSA, and IAA accelerators, which boost performance in compression, encryption, data movement, and data analytics workloads. These functions typically require external I/O, and using the lesser Intel 7 transistors for these functions preserves the more expensive Intel 3 transistors for compute functions.
Unfortunately, Intel’s accelerator blocks have a vulnerability that renders them unsafe for use in VMs. The vulnerability doesn’t cause an issue if the accelerators are unused, but they must be restricted from use in VMs. Phoronix reports this is a hardware issue, meaning a software patch won’t address the problem. It appears the issue won’t be addressed in silicon until the Diamond Rapids and Granite Rapids D processors arrive. We’re following up with Intel for clarification.
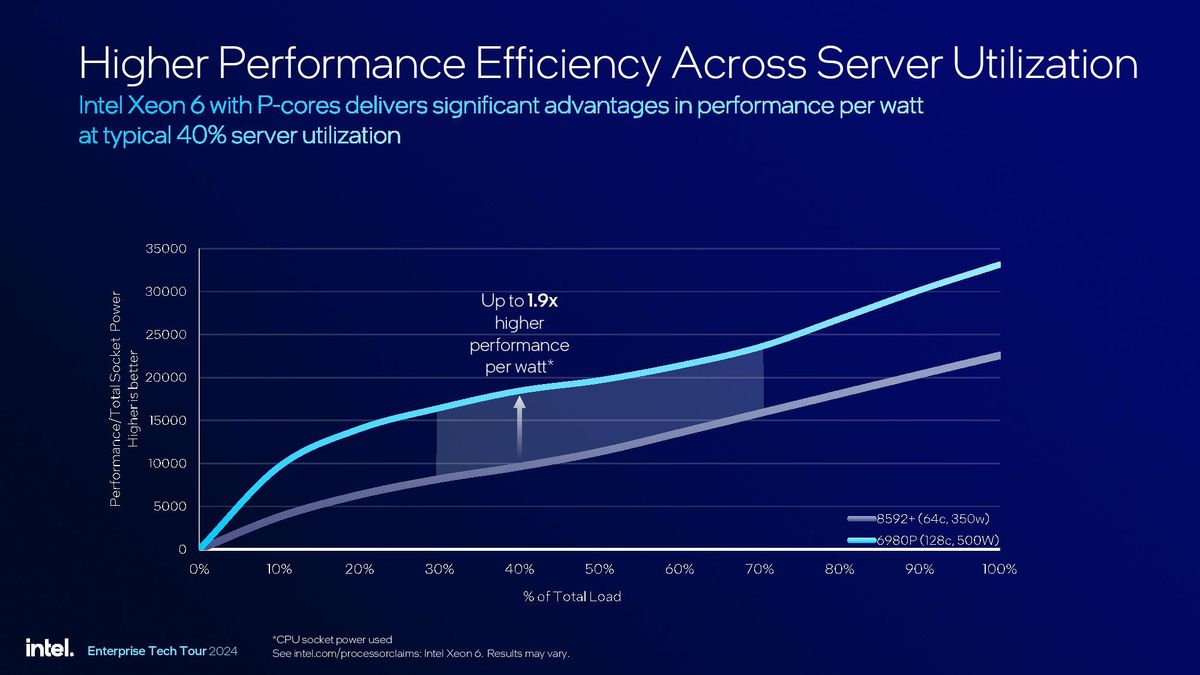
As we saw with the prior-gen Emerald Rapids, Intel continues to focus on improving power efficiency when the chip is under lighter loads. This focus is because most servers typically operate anywhere from a 30% to 50% utilization, with full-load scenarios being somewhat rare in modern deployments.
Through a combination of its newer process node and microarchitecture, along with refined power management optimizations that dynamically modulate multiple facets, including uncore/fabric frequencies, Intel claims up to a 1.9X improvement in performance-per-watt at 40% utilization. However, the impact varies at different load levels, though the entire CPU utilization load-line range shows a marked improvement over the prior-gen Xeon 8592+.
This functionality was wrapped in an ‘optimized power mode’ setting with the prior-gen Xeon models, but Intel says it has now reduced the tradeoffs of this mode to the negligible range. As such, Intel’s Xeon 6 now runs in this mode by default.
Image 1 of 3
The AP platform has 12 memory channels but only supports one DIMM per channel (1DPC). With standard memory, the platform supports up to DDR5-6400, which increases to 8800 MT/s with specialized Multiplexed Rank DIMMs (MRDIMMs). As shown on the right side of the first chart above, Intel claims MRDIMM-8800 offers up to 1.33x more performance in memory throughput-sensitive workloads, like certain AI and HPC applications, over standard DDR5-6400 memory (notably, the ResNet50 benchmark is with the 96-core Xeon 6, not the 128-core model).
MRDIMMs are a JEDEC-standard memory (originally championed by AMD) that leverage multiple memory banks operating in lockstep, thus boosting performance beyond a standard memory DIMM. This type of DIMM requires hardware-based support in the memory controller, and Intel claims to be the first to market with support for this new memory tech. Intel says MRDIMMs provide the same or better latency than standard DDR5, but they’ll naturally come at a cost premium.
MRDIMMs are not to be confused with the performance-boosting MCRDIMMs (originally championed by Intel), which are faster but more complex and aren’t officially JEDEC-ratified. Intel supported MCRDIMMs with its previous generation Xeon, but has now shifted to MRDIMMs.
Memory capacity and bandwidth are becoming more pressing issues, especially for AI workloads and in-memory databases. ComputeExpress Link (CXL) is designed to help address those needs (among others). Granite Rapids supports Type 1, Type 2, and Type 3 CXL 2.0 devices, and we can expect this type of support from AMD’s future platforms as well.
Intel says its customers are most interested in combining economical DDR4 memory with CXL devices to boost memory capacity for DDR5-equipped servers, thus reducing cost (many simply plan to repurpose the DDR4 from their older servers). The CXL consortium initially told us of strong industry interest in this type of arrangement a few years ago, but Intel says it now foresees production-level deployments on the near horizon.
Intel feels well positioned for this market due to its unique Flat Memory Mode, largely derived from its learnings with the now-dead Optane DIMMs. This feature creates one large pool of memory from both the standard direct-attached DDR5 memory DIMMs and remote Type 3 CXL memory devices with DDR4 connected via the PCIe lanes. Intel’s approach is hardware-assisted – the tech is built into the memory controller and isn’t software-based like other memory tiering solutions. As such, it doesn’t incur any CPU overhead and operates regardless of the host operating system.
Intel shared benchmarks showing the benefits of a combined memory pool of DDR4 and DDR5, with the memory controller intelligently placing data on the correct pool based on several variables. The company claims a 3% performance loss for an in-memory OLAP database, showing a minimal performance loss despite having 1/3 of the pool comprised of slower DDR4 memory.
AI and HPC Benchmarks
Image 1 of 7
Above, you can find Intel’s performance claims, and we have an album at the end of the article that includes all the benchmarking footnotes. As always with vendor-provided benchmarks, approach these results with caution.
Many of Intel’s comparisons are against its fifth-gen Xeon models, showing strong improvements in both performance and power efficiency across a broad range of general compute, data and web services, HPC, and AI workloads. Notably, these benchmarks employ varying core counts and memory types (DDR5, MRDIMM) for individual comparisons. Overall, Intel claims 1.2x higher average performance-per-core, 1.6X higher performance-per-watt, and 30% lower average TCO than its fifth-gen Xeon comparables.
Naturally, no comparison would be complete without benchmarks against AMD’s EPYC. To highlight its claimed advantages in virtualized environments, Intel also provided benchmarks against AMD’s fourth-gen EPYC ‘Genoa’ chips, claiming up to 2.88x more performance in ResNet50 workloads in a 16 vCPU VM workload, along with advantages in a slew of other workloads like BERT-large, LAMMPS, and NGINX, among others.
Intel also provided more benchmarks against both AMD’s Bergamo and Genoa chips in general compute, data services, and web services. Intel also provided a range of HPC benchmarks against the EPYC 9654 with both standard DDR5 and MRDIMMs, but be sure to pay attention to the footnotes below when assessing these results.
Image 1 of 7
AI is soaking up much of the data center spend right now, which will likely continue for the foreseeable future. As such, Intel is keen to demonstrate its advantages in AI workloads with its Advanced Matix Extensions (AMX), which now also supports FP16 in addition to the existing support for INT8 and Bfloat16.
Intel sees its AI CPU advantage taking three forms: raw AI compute on the CPU, CPU performance and support when paired with AI GPUs, and performance in vectorized databases that run on the CPU to augment AI training workloads.
Intel compared its 96-core Xeon 6972P against the EPYC Genoa 9654 and prior-gen Xeon 8592+ to highlight claimed advantages across a broad range of locally-run AI workloads.
Naturally, the real competitor here is AMD’s upcoming Turin, but Intel doesn’t have those chips available for comparison. Instead, Intel shared a slide that leveraged the Turin AI benchmarks that AMD shared during its Computex keynote. Intel wasn’t happy with those benchmarks, and it doubled down on its retort with a new round of benchmarks with the new Xeon 6980P vs the 128-core Turin, claiming a 2.1x lead in Summarization, 5.4x lead with a chatbot, and 1.17x lead with a Translation workload. Naturally, we expect AMD to respond when it launches Turin next month.
Intel also wants its chips to be a good pairing for not only systems equipped with Nvidia GPUs but for all servers with discrete accelerators – including its own Gaudi 3. Intel says it has multiple Xeon 6 models qualified for use with Nvidia’s MGX systems, citing that as a proof point of its claimed superior CPU performance that pushes AI GPUs to their limits. Intel also claims higher single-thread CPU performance, I/O performance, higher memory bandwidth and capacity, along with support for DC-MHS and Nvidia’s MGX standards, solidifies its position.
Finally, Intel also touted its AMX support as an advantage in vector databases. Intel’s Scalable Vector Search (SVS) library boosted indexing and search over the EPYC 9654 in the company’s benchmarks. These types of databases can be used in tandem with AI RAG workloads, wherein the vector database stores the embeddings for the data set used for training. Naturally, excelling at this type of workload augments the GPUs and could help streamline the training process.
Thoughts
Intel’s Xeon 6 lineup finally brings it toe-to-toe with AMD’s traditional advantage in core counts, but the true story will be told in independent benchmarking and cost analysis of the differing platforms. Notably absent in Intel’s presentations? Benchmark comparisons to competing Arm server chips. Arm has steadily clawed its way into the data center, largely through custom models deployed by hyperscalers and cloud providers. That does make direct comparisons a bit tough, but we hope to see some virtualization comparisons against the Arm competition in the future.
Intel’s Xeon 6700P series launches today worldwide, and the follow-on models come in Q1 2025. We’re busy putting a Xeon 6 server platform to the test — stay tuned for benchmarks.
Image 1 of 16
#Intel #Launches #Granite #Rapids #Xeon #6900P #series #cores #matches #AMD #EPYCs #core #counts #time