
{kind=link}
On-Premises vs. Cloud Data Warehouses: Pros and Cons
Data warehouses are widely used by organizations of all sizes to ingest, store and process large amounts of data for BI and analytics applications. They emerged in the 1990s and are a mature, mainstream technology. Nowadays, though, one of the big decisions for an organization that’s looking to deploy a data warehouse is whether to put it on premises or in the cloud.
As with other types of IT systems, a cloud data warehouse offers various benefits over an on-premises installation — for example, easy scalability, more flexibility and less routine management work for database administrators (DBAs). But each organization has its own set of needs and priorities, which warrants a comparison of the cloud vs. on-premises options before planning a data warehouse deployment. To help with that, let’s look more closely at the two approaches and their advantages and disadvantages.
Traditional vs. cloud data warehouse architectures
A high-quality computing environment — server, OS, storage and database all included — is critical to the success of any application that uses lots of data. That definitely applies to data warehousing: In order to select the best data warehouse platform for their organization, IT and data management teams need to evaluate full system environments, not just the database software at the heart of them.
A traditional data warehouse architecture consists of the following three tiers:
- A bottom tier with a database server that houses the data warehouse itself.
- A middle tier where data is processed for analysis, commonly by an online analytical processing engine.
- A top tier that serves as a presentation layer and front-end interface for BI and analytics tools.
An enterprise data warehouse stores data from all of an organization’s business operations in a single, centralized platform; on the other hand, data marts are smaller warehousing systems that contain subsets of data for particular departments, business units or groups of users. Both are often included in a data warehouse architecture, and the following are the two primary methods of designing one — a choice that’s often referred to in shorthand as Inmon vs. Kimball:
- Top-down approach. Created by computer scientist, author and vendor executive Bill Inmon, this method starts with the enterprise data warehouse and then uses the data sets stored in it to set up various data marts.
- Bottom-up approach. Consultant Ralph Kimball flipped things around by developing this alternative method, in which separate data marts are built and then integrated to produce an enterprise data warehouse.
Using those traditional concepts, the cloud enables data warehouse vendors to customize their underlying hardware and software architectures to meet different processing needs. Here are some prominent examples of cloud data warehouse offerings, listed in alphabetical order.
Autonomous Database for analytics and data warehousing
Oracle’s flagship system for analytics data in the cloud is built on top of Oracle Database and the Oracle Exadata computing platform. The system is available in shared or dedicated infrastructure deployments and can also be installed on premises through Oracle’s Cloud@Customer service. Oracle’s shared infrastructure option is a more traditional cloud service, while the dedicated one offers customers a totally private environment in the public cloud with their own compute, storage, network and database resources.
Azure Synapse Analytics
Microsoft’s cloud analytics service offers serverless and dedicated resource models and uses a distributed SQL processing engine called Synapse SQL to run data warehouse queries. It also includes Apache Spark as a big data analytics engine and Azure Data Lake Storage Gen2 as its data store. The platform is based on a scale-out massively parallel processing (MPP) architecture that distributes workloads across multiple nodes and separates computing resources from storage, enabling customers to scale each independently.
BigQuery
Google BigQuery is a serverless cloud data warehouse with a SQL-based, distributed MPP analysis engine that stores the bulk of its data in tables. Each table column is stored separately, which enables BigQuery to scan individual columns over an entire data set more efficiently than traditional row-based storage. BigQuery uses both partitioning and clustering to provide high-performance data access. It also supports multi-cloud data warehouse deployments and includes engines for machine learning, predictive modeling and geospatial analysis.
Redshift
Amazon Redshift from AWS uses clusters to provision one or more computing nodes for running analytics applications in data warehouses, operational databases and data lakes. AWS offers a serverless option, a machine learning module and native integration with a variety of its other cloud services, including BI, data integration and big data processing tools. Like BigQuery, Redshift stores each table column separately; it also provides an automated table optimization feature to boost query speeds in clusters by improving the physical layout of data sets.
Snowflake
Unlike most of its competitors, Snowflake’s data warehouse system was built to run across the AWS, Azure and Google Cloud platforms. Snowflake describes its processing environment as a hybrid shared-disk/shared-nothing architecture. The product uses a central repository to share data across the environment and multiple MPP computing clusters to separate workloads, with each node in a cluster storing a portion of a data set locally. Delivered as a fully managed service, Snowflake also supports data lake, data engineering and data science workloads.
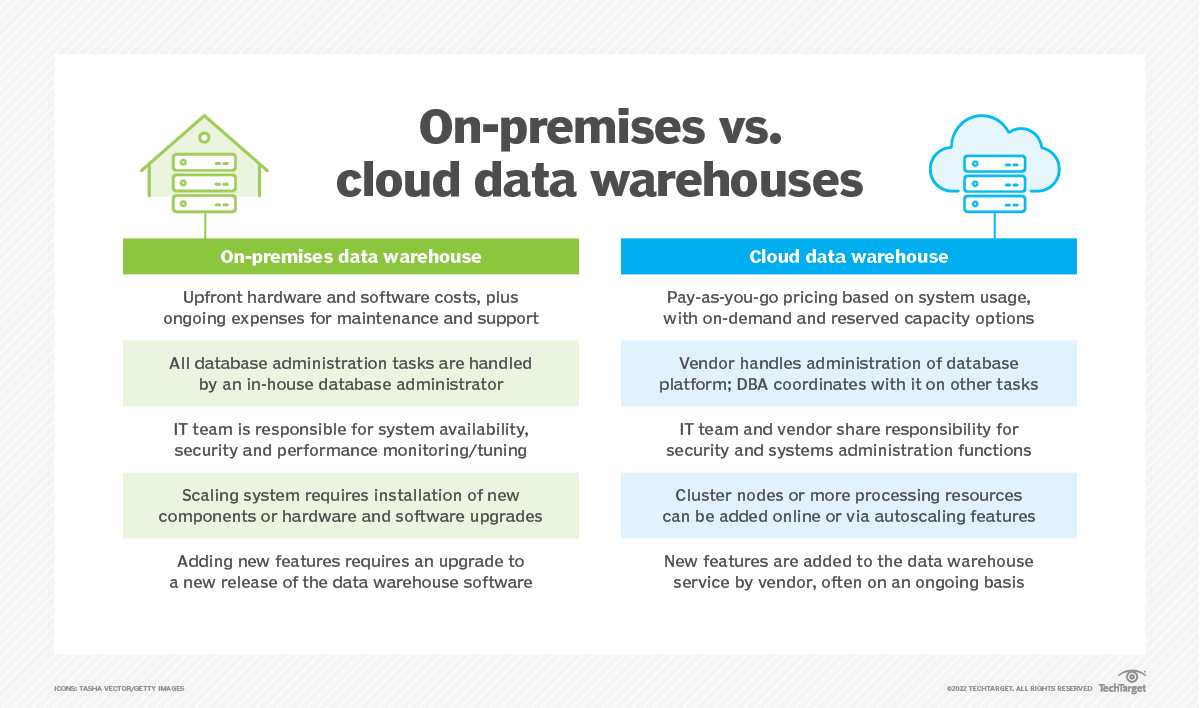
Pros and cons of cloud vs. on-premises data warehouses
A big challenge for on-premises data warehouses is the need to deploy a hardware and software computing environment that meets the organization’s data architecture and processing requirements. The hardware support team, systems administrators and DBAs work together with the data warehouse software vendor to build the environment, which typically is complex and requires a separate team to be allocated for administration and support. In addition, scaling on-premises systems to meet ever-increasing data storage and workload growth can be costly and time-consuming.
But cloud data warehouses can also pose some challenges to organizations and require changes in IT processes. Here are more details on the pluses and minuses of the two approaches in some key areas.
1. Costs
It’s clear that the cost of deploying and supporting a data warehouse system in an on-premises data center usually will be much higher than renting one from a cloud provider with usage-based payments. That’s especially so with a data warehouse as a service (DWaaS) environment fully managed by the vendor. But the cloud vs. on-premises cost comparison isn’t as simple for organizations that already have investments in existing data centers.
The initial selling point for cloud platforms was the ability to reduce IT costs. But organizations implementing applications in the cloud quickly realized that cost savings isn’t always one of its advantages. Organizations might not have to purchase servers and software for cloud data warehouse systems, but the cost of using compute, memory and disk resources from a cloud vendor can add up, particularly if data warehouse workloads increase unexpectedly.
Of course, system costs aren’t the only expense that IT teams need to consider when they compare on-premises and cloud platforms. The labor costs required to support the environments must be factored in, too. For on-premises ones, this includes administrative support for the computing hardware, OS, disk storage and database. Cloud data warehouses don’t completely eliminate support costs; even in a DWaaS environment, DBAs still have administrative tasks to handle, for example. But such costs typically are much lower in the cloud.
There also are other costs that often get overlooked. Organizations deploying data warehouses in the public cloud don’t incur direct costs for regulatory compliance certifications, data center environmental controls, energy consumption, high availability and disaster recovery configurations, and system improvements. Those elements are built into the cost of the cloud service, and some can result in higher usage fees for an organization, but the vendor pays the tab for them.
2. New features and functionality
The cloud data warehouse market is hotly contested, which compels all of the vendors to maximize their feature sets. Continual innovation and integration of new features in an effort to differentiate their products from rival ones is an absolute requirement. As a result, cloud data warehouse users are able to take advantage of a constant stream of new features and functionality.
In addition, because cloud vendors assume responsibility for the entire data warehouse system, their customers can benefit from enhancements that range from the underlying computing infrastructure to the data warehouse software itself. Upgrading systems and deploying new software releases is more complicated for on-premises users that manage their own environments. New features also might not become available as quickly in on-premises data warehouse software as they do in cloud services that can be updated by vendors on an ongoing basis.
Another potential plus in the cloud: To complement their core data warehouse capabilities for basic BI and reporting uses, the top cloud vendors listed above and other competitors all offer additional technologies and features that support data lakes, machine learning, big data analytics, data pipeline development and other functions for advanced analytics applications.
3. Scalability
System scalability helps IT teams contend with the growth of processing workloads. When performance tuning and updating software configurations no longer have a positive impact on system throughput, adding disk, memory and computing capacity becomes necessary. Scalability is also important for data warehouses in order to accommodate data growth when new source systems are added.
But scaling an on-premises data warehouse platform can be a real chore. If the server has the capacity to increase CPU or memory, a sys admin needs to open the chassis and replace or add components. For servers that don’t have additional capacity available, the hardware needs to be upgraded to a bigger system. Clustered environments provide horizontal scaling that enables more servers to be added, but hardware, software and administration costs can quickly become excessive.
One of the key selling points for cloud platforms is their ease of scalability. For example, Amazon Redshift users can quickly add nodes to their environment to get better performance and more storage. Oracle’s Autonomous Database takes things one step further by offering an autoscaling feature, which can automatically increase computing or storage resources. AWS and Snowflake provide similar concurrency scaling features that can automatically add cluster capacity when workloads increase.
4. Performance monitoring and tuning
For optimizing the performance of a data warehouse, on-premises platforms often require IT teams to use separate tools to monitor the hardware, OS and database. Because cloud vendors are able to customize their performance monitoring tools and advisor utilities to their data warehouse infrastructure, the tools often provide more comprehensive information than on-premises ones.
However, in addition to standard database performance tuning challenges, cloud platforms add another dimension to performance monitoring and troubleshooting. Transferring data into and out of a cloud data warehouse system can be challenging, especially if there are large data volumes and tight time constraints. Also, organizations that implement data warehouses on cloud platforms aren’t totally responsible for performance. When system performance is suspect and scaling isn’t an option or doesn’t fix the problem, an organization will have to work with its cloud provider to identify the root cause.
Even worse, when resources are overutilized, cloud data warehouse systems might arbitrarily stop your workloads. It only takes a few improperly tuned queries to spike resource consumption in any database environment, on premises or in the cloud. But sustained increases in cloud resource utilization might result in your organization being forced to upgrade to a higher performance tier.
5. Management control
In on-premises environments, the IT department has total control of — and full responsibility for — its computing systems. For cloud data warehouses, it shares those responsibilities with the vendor. Especially in a fully managed DWaaS environment, you’ll give up some ownership of managing the data warehouse platform.
Some IT shops will view this as a benefit, others as a risk, but most will likely see it as a combination of risk and reward. All of the leading cloud data warehouse providers offer service-level agreements that guarantee minimum uptime percentages, which should help to reduce concerns about a loss of control over systems.
6. Security
Likewise, organizations that deploy on-premises data warehouses are responsible for securing the entire environment — from the hardware infrastructure on up the software stack. In the cloud, though, security responsibilities are shared with the provider. It’s important to understand that your organization doesn’t turn over 100% of the responsibility for security to the vendor. Under the shared responsibility model for cloud security, the customer still needs to handle some aspects of securing a data warehouse environment.
How the responsibilities are split might vary from vendor to vendor. It also depends on whether an organization is using a managed DWaaS environment or an IaaS one, in which the vendor typically is responsible only for securing the underlying IT infrastructure. In general, though, the IT team retains responsibility for tasks such as data security, data classification, access control and endpoint device security.
Standard security best practices apply to both on-premises and cloud platforms, but organizations that use cloud data warehouse systems are able to share the costs of securing their environments with the provider. Being able to take advantage of the vendor’s security capabilities is another plus. Cloud providers have an obvious incentive to ensure that their platforms are secure, and they invest a lot of money in an effort to do so.
7. Auditing and regulatory compliance
As noted above, one of the benefits of a cloud data warehouse is that the vendor assumes responsibility for the underlying architecture. But this can present a challenge to organizations that need to adhere to industry or regulatory compliance rules, as well as internal standards.
Much like security, compliance is a shared responsibility between the customer and cloud provider. The vendor typically will provide third-party auditor compliance reports and attestations for HIPAA, GDPR and other compliance frameworks. But an organization must work with the vendor to collect the required supporting evidence to verify that a data warehouse system complies with applicable frameworks, based on the organization’s specific auditing needs.
Although using the cloud can make it more time-consuming to find the evidence you need, passing along some of the costs of regulatory compliance to your cloud vendor should outweigh the inconvenience.
Chris Foot is a former senior strategist for managed services at RadixBay, an IT consulting and services provider. Before he retired in 2023, Chris was responsible for optimizing the managed services experience for RadixBay’s clients. He also acted as a strategic advisor to them on the use of leading-edge cloud and on-premises data infrastructure technologies.
#OnPremises #Cloud #Data #Warehouses #Pros #Cons